
ACM SIGMETRICS 2026
Ann Arbor, Michigan, USA
June 8-12, 2026
ACM SIGMETRICS 2026
Ann Arbor, Michigan, USA
June 8-12, 2026
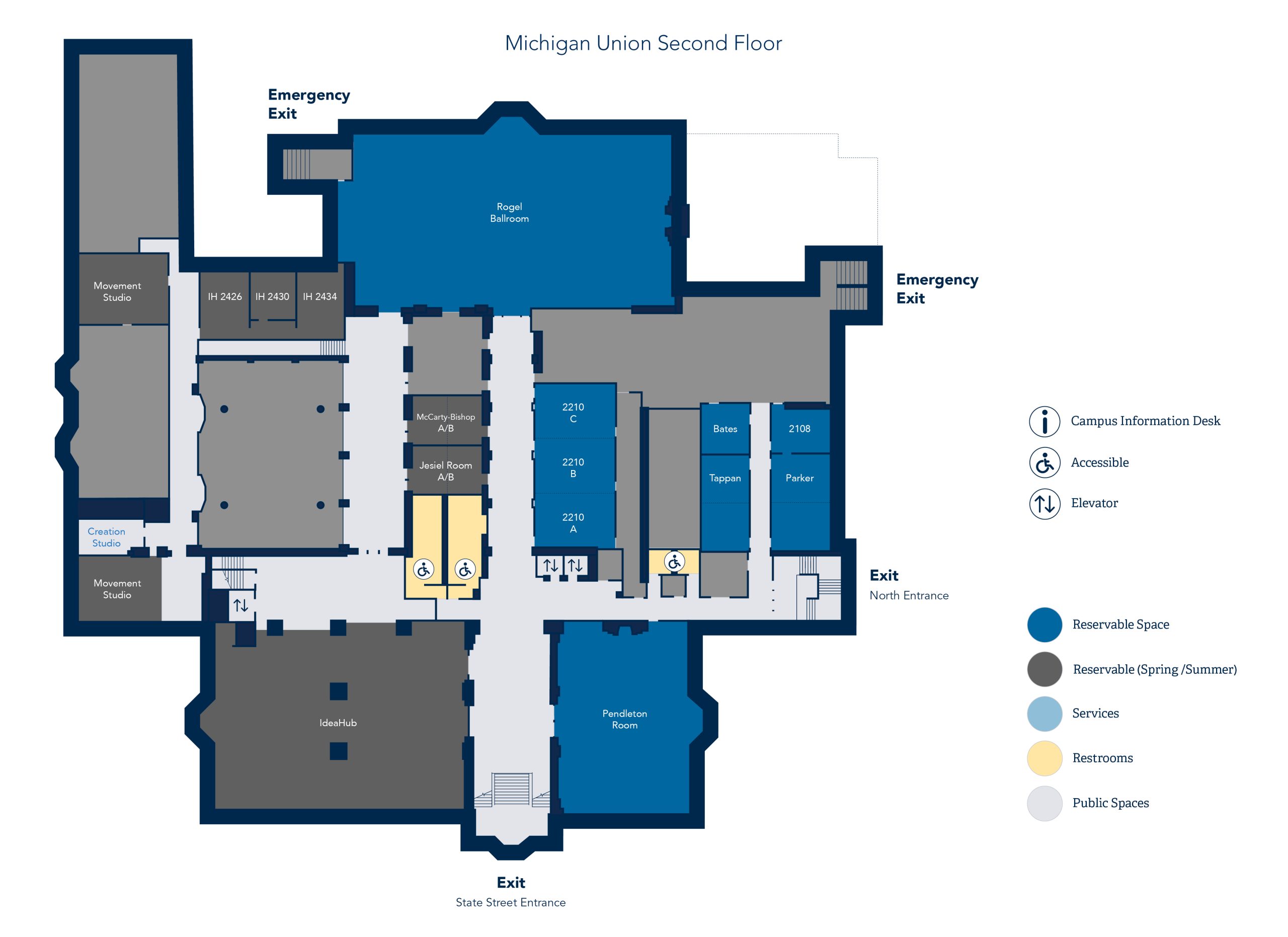
Michigan Union: 530 S. State Street Ann Arbor, MI 48103
Most of the talks will be situated on the second floor
Use either eduroam, or Mguest for visitors. Click here for details
SIGMETRICS 2026 will feature four tutorials organized across two parallel tracks. Find the detailed schedule below.
| 7:30 am | REGISTRATION | ||
|---|---|---|---|
| 8:00 am | |||
| 8:30 am | Light breakfast | ||
| 9:00 am | Causal Survival Analysis | Efficient Large Language Model Inference | |
| 9:30 am | |||
| 10:00 am | |||
| 10:30 am | Coffee break: Idea Hub -- 30 min | ||
| 11:00 am | Causal Survival Analysis | Efficient Large Language Model Inference | |
| 11:30 am | |||
| 12:00 pm | |||
| 12:30 pm | Lunch | ||
| 1:00 pm | |||
| 1:30 pm | CANCELED |
Structure Exploiting Multi-Agent Reinforcement Learning for Networked Systems | |
| 2:00 pm | |||
| 2:30 pm | |||
| 3:00 pm | Break 30 min | ||
| 3:30 pm | Mentoring Workshop | ||
| 4:00 pm | |||
| 4:30 pm | |||
| 5:00 pm | |||
| 5:30 pm | TPC dinner | ||
| 6:00 pm | |||
| 6:30 pm | |||
| 7:00 pm | |||
Duration: 3 hours
Speakers: Jessy Han (MIT), George Chen (Carnegie Mellon), Devavrat Shah (MIT)
Many applications involve reasoning about the amount of time that will elapse before a critical event happens. When will a hard drive fail, a customer cancel a subscription, a patient get discharged from the hospital, or a convicted criminal reoffend? These time durations are referred to as time-to-event outcomes. Modeling time-to-event outcomes under partial observation, i.e., censoring, has been extensively studied within the fields of survival analysis and reliability engineering for decades. This tutorial aims to bring the audience up to speed on the basics as well as modern developments of survival analysis, with a heavy emphasis on the growing active area of research on causal survival analysis, where time-to-event outcomes arise under interventions whose effects must be inferred from nonrandomized observational data using causal inference. We provide a lay of the land of the major categories of causal survival analysis methods available today, how to benchmark causal survival methods, and open questions.
Jessy (Xinyi) Han. Jessy (Xinyi) Han is a Ph.D. candidate at the Massachusetts Institute of Technology and an incoming Assistant Professor (institution to be decided). Her research develops methods in causal inference and survival analysis to enable when-if decision-making, a framework for understanding how interventions affect not only what happens but when it happens. She works closely with practitioners to bring these methods into high-impact domains, including healthcare, policy evaluation, and business strategy. She is a recipient of the Google-MIT Schwarzman College of Computing Fellowship.
George H. Chen. George H. Chen is an Associate Professor in Carnegie Mellon University's Heinz College of Information Systems and Public Policy. He studies trustworthy machine learning methods for reasoning about time, often in the context of health applications. Much of his work is on predicting time durations before critical events happen (also called time-to-event prediction or survival analysis), or on analyzing time series such as electronic health records and EEG data. He is interested in developing new methods for these time-related problems as well as understanding when and why these methods work in terms of statistical guarantees. George completed his Ph.D. in Electrical Engineering and Computer Science at MIT, where he won the George Sprowls Award for outstanding Ph.D. thesis in computer science and the Goodwin Medal, the top teaching award given to graduate students. He is a recipient of an NSF CAREER Award and has also co-founded CoolCrop, a startup that provides cold storage and marketing analytics to rural farmers in India.
Devavrat Shah. Devavrat Shah is the Andrew (1956) and Erna Viterbi Professor in MIT's Department of Electrical Engineering and Computer Science and is a member of the Institute for Data, Systems and Society, Laboratory for Information and Decision Systems, and the Statistics and Data Science Center. His research focuses on statistical inference and stochastic networks, and his contributions span a variety of areas including resource allocation in communications networks, inference and learning on graphical models, and algorithms for social data processing, including ranking, recommendations, and crowdsourcing. Within networks, his work spans a range of areas across electrical engineering, computer science, and operations research. He earned a BS in computer science and engineering from the Indian Institute of Technology and a Ph.D. in computer science from Stanford University. His work has been recognized through prize paper awards in machine learning, operations research, and computer science, as well as career prizes including the 2025 ACM SIGMETRICS Achievement Award, the 2010 Erlang Prize from the INFORMS Applied Probability Society, and the 2008 ACM SIGMETRICS Rising Star Award.
Duration: 3 hours
Speakers: Ankur Mallick (Microsoft), Srikant Bharadwaj (Microsoft)
Large Language Models (LLMs) have become a foundational component of modern interactive systems, yet deploying them at scale remains extraordinarily expensive and complex. While recent advances in model architecture and training have received significant attention, inference efficiency, especially under latency-sensitive and highly variable workloads, has emerged as a critical bottleneck. For the SIGMETRICS community, LLM inference presents a rare convergence of hardware-aware performance modeling, online scheduling, and queueing-theoretic trade-offs at unprecedented scale. This tutorial will provide a systematic, end-to-end view of efficient LLM inference, spanning GPU execution models, batching and scheduling algorithms, and analytical and statistical simulation techniques for capacity planning and performance optimization.
We will begin by demystifying how modern GPUs execute transformer workloads, highlighting the distinct computational and memory characteristics of the prefill and decode phases, and explaining why traditional throughput-centric optimization strategies often fail under realistic service-level objectives (SLOs). We will show how GPU micro-architecture, kernel behavior, batching granularity, and memory hierarchies jointly shape latency and efficiency envelopes.
Next, we will dive into batching and scheduling algorithms for LLM serving, including continuous batching, paged attention, prefill chunking, and multi-stage (prefill/decode) deployments. We will frame these techniques through a metrics-driven lens, emphasizing the inherent throughput-latency-fairness trade-offs that arise under heterogeneous request sizes and bursty arrivals. Drawing on recent research and large-scale production experience, we will highlight open challenges in operating LLM services near their optimal efficiency frontier without triggering catastrophic tail-latency degradation.
Finally, we will introduce an analytical and statistical LLM inference simulator developed by the speakers' team that combines hardware-level performance models with queueing and workload distributions to predict end-to-end latency, batching behavior, and utilization. Unlike trace-driven or full discrete-event simulators, this approach enables fast what-if analysis, principled identification of optimal operating points, and quantitative evaluation of scheduling, caching, and hardware trade-offs. We will present a live demo of the simulator, discuss its validation against real deployments, and outline how researchers and practitioners can use it to reason about LLM inference systems using the language of SIGMETRICS: arrival processes, service rates, queueing delay, and tail latencies.
Overall, this tutorial aims to bridge the gap between LLM systems research and performance modeling, equipping the SIGMETRICS audience with the conceptual tools, models, and abstractions needed to analyze and design efficient, reliable LLM inference services at scale.
Duration: 1.5 hours
Speaker: Guannan Qu (Carnegie Mellon)
Networked systems like energy networks, traffic networks, etc. are ubiquitous and play an indispensable role in advancing our modern society. The decision-making and operation of such systems have long been a tremendous challenge. In the meantime, the recent advancement of machine learning, particularly reinforcement learning, has achieved tremendous success across different domains, exhibiting impressive capability to learn to control complex and unknown systems. Due to these advantages of reinforcement learning, it has been recognized to hold great potential for revolutionizing the way we operate these large-scale networked systems. However, despite a rich literature on reinforcement learning and multi-agent reinforcement learning, these algorithms are widely recognized to suffer from scalability, stability, and safety issues when it comes to large-scale networked systems. To address these challenges, there have been recent lines of work in the literature that exploit structural properties of networked systems to design more scalable multi-agent reinforcement learning algorithms. Examples of the structural properties include the sparse network topology, the locality property in multi-robot systems, and homogeneity in queueing systems. This tutorial provides a holistic overview of these results, covering various types of structural properties and how to integrate these properties into multi-agent reinforcement learning.
Guannan Qu is an Assistant Professor in the Electrical and Computer Engineering Department at Carnegie Mellon University. He joined the department in September 2021. He received his Ph.D. in applied mathematics from Harvard University in 2019 and was a postdoctoral scholar in the Department of Computing and Mathematical Sciences at the California Institute of Technology from 2019 to 2021. He is the recipient of an NSF CAREER Award, an ICRA Best Paper Finalist recognition, the Best Paper Award from the AAAI 2025 Workshop on Multi-Agent AI in the Real World, the Caltech Simoudis Discovery Award, a PIMCO Fellowship, and the IEEE SmartGridComm Best Student Paper Award. His research interests lie in control, optimization, and machine and reinforcement learning.
Duration: 1.5 hours
Speaker: Mengdi Wang (Princeton University)
Recent advances in large foundation models, such as large language models and diffusion models, have
demonstrated impressive capabilities. However, to truly align these models with user feedback or maximize
real-world objectives, it is crucial to exert control over the decoding processes in order to steer the
distribution of generated output. In this tutorial, we will explore methods and theory for controlled
generation within large language models and diffusion models. We will discuss various modalities for
achieving this control, focusing on applications such as LLM alignment, accelerated inference, transfer
learning, and diffusion-based optimization.
Mengdi Wang is a Professor of Electrical and Computer Engineering and the Center for Statistics and Machine
Learning, and by courtesy, Computer Science and Bioengineering, at Princeton University. She founded and
co-directs Princeton AI^2, Princeton AI for Accelerating Invention. Her research spans generative AI,
reinforcement learning, and large language models, with a focus on efficient fine-tuning, LLM reasoning,
AI agents, AI for biotech, and automated science. She works closely with scientists and practitioners to
implement AI algorithms, handle real-world data and systems, and apply AI technology to improve decision
making and accelerate scientific discovery. She has received multiple honors, including the NSF CAREER
Award, a Google Award, MIT Tech35, and the Donald Eckman Award for extraordinary contributions to the
intersection of control, dynamical systems, machine learning, and information theory.
{kind=link}